downloading a neocities site with wget
neocities includes a handy button to download a copy of your blog. however i've had it disappear on me before, and searching reveals it has for other people too, so i wanted an alternate method just in case.

the command line program wget downloads files from the internet and works especially well on neocities. it's available for windows, mac and linux, installation is different for each one. macos can get it from the homebrew package manager, linux can also get it from homebrew but likely has it pre-installed, windows... idk :p
it takes one command to download a whole neocities site.
explanation for the arguments used:
-m, aka--mirror: download sub directories-p, aka--page-requisites: download prerequisite files like images, fonts, css and javascript-E, aka--adjust-extension: save html and css documents with proper extension. (links to other sites are not downloaded, but the links stay intact)
the hyperlinks will still point to the site hosted on neocities, which is ideal for a backup that you can simply reupload if something goes wrong with the original. however if you'd like a fully offline browseable version, change the argument to -mpEk. -k, aka --convert-links, changes links from the absolute path to your website to the relative path of the downloaded files (meaning you can move it around from where you initially downloaded it too). since most neocities sites are under 1 gb, there's little reason not to grab both versions. (you also may not need this option if you wrote your site with relative links to begin with)
ymmv in regards to download time. on my laptop near the router my image-heavy transformers fansite took 2 minutes to download, on my desktop in my room it took 40 minutes.
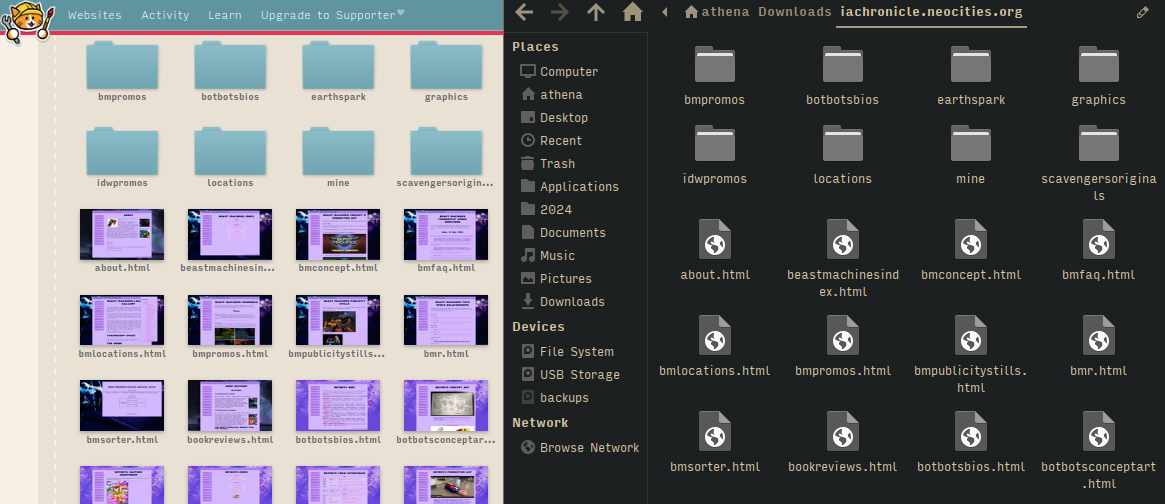
download files that haven't been linked to
you may find that using wget in this way only fetches files that are "public" in the sense that they are linked somewhere. getting "private" files that are not linked is more involved, but possible. (at least on linux)
open your site's neocities dashboard and enter the directory you want to download from. right click and then click Save Page As, choose either incomplete html (without images and other assets) or plain text. there are a LOT of lines, and some of them have the files we want to download. for example:
wget can read a list of links from a file, however the downloaded web page won't work as-is, it needs some editing first. use the search tool grep to search for the lines we want to save, which are the ones that start with your site's url. pipe to sed to isolate the links from all the html brackets and such surrounding them (source). the result should be clean urls, all on their own lines. output that to a new file for wget to read from. the whole command looks like this:
make and enter a directory to download into (assuming you want to be organized) use wget with the -i flag to input a list of links from a file: